|
Jerry (Jiarui) Zhang I am a final-year Computer Science Ph.D. student at USC, advised by Willie Neiswanger. Previously, I received my bachelor's degree in electrical engineering from Tsinghua University. I grew up in Dalian, a beautiful coastal city in China. My Chinese name is 张家瑞. |

|
|
I'm very happy to chat about research ideas and collaborate with people. Please feel free to reach out to me if you are interested in discussing or working together! |
ResearchMy research focuses on multimodal learning and reasoning, and I'm interested in AI-for-Science. |
|
Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions
Jiarui Zhang Ollie Liu, Tianyu Yu, Jinyi Hu, Willie Neiswanger, Arxiv, 2024 arXiv, code, model & dataset, demo
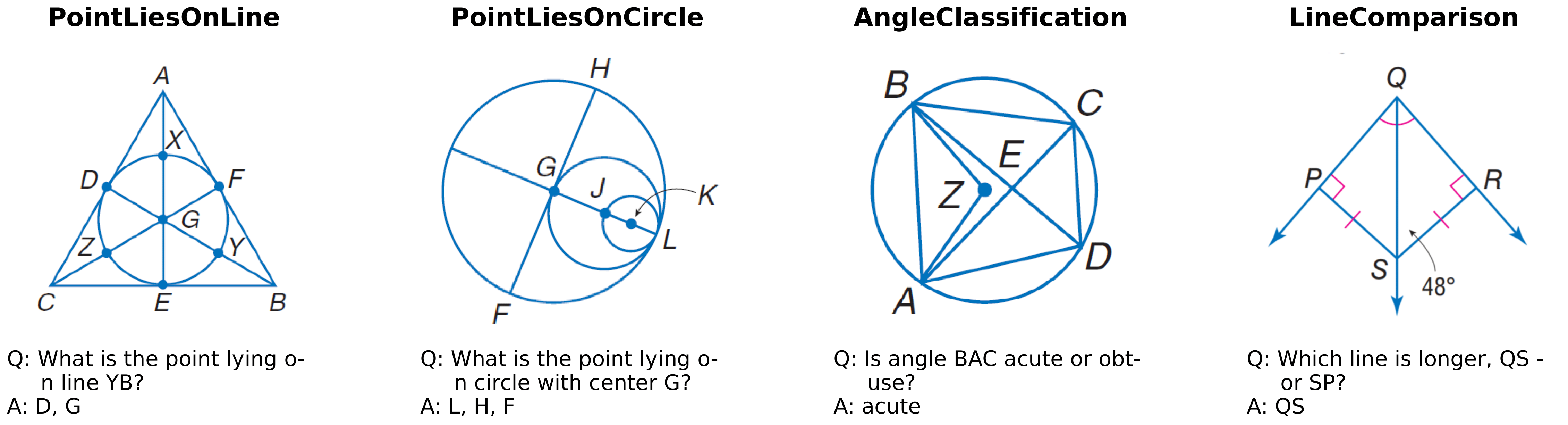
A study of low-level visual perception (LLVP) in multimodal LLMs in 2D-geometry domain including |
|
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
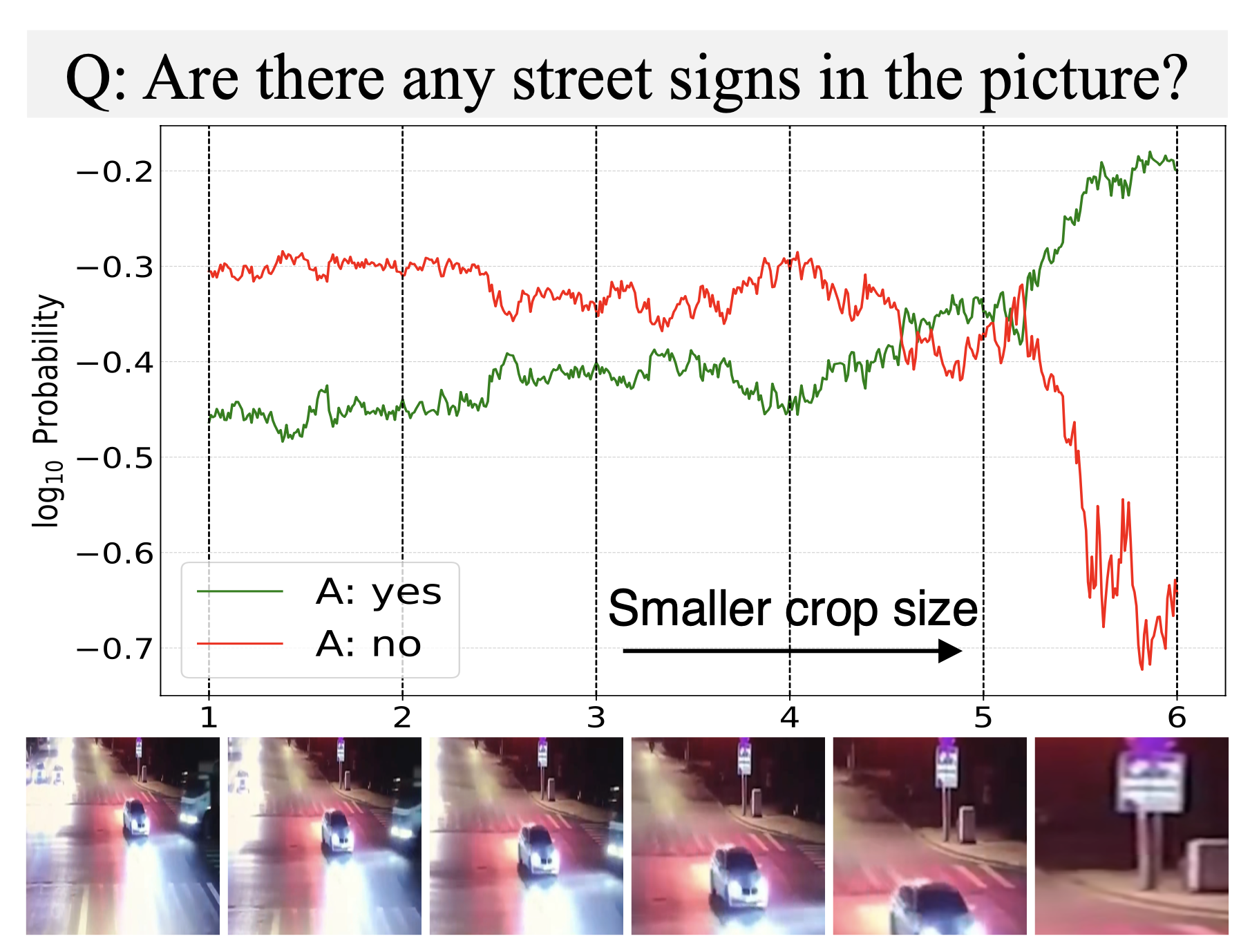
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, Filip Ilievski ICLR, 2025 arXiv, Github We address MLLMs' limitation in perceiving small details without training. Specifically, we show that cropping the relevant regions according to MLLMs' own attention significantly improves performance, while revealing that MLLMs do know where to look but often fail to perceive fine details. |
|
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
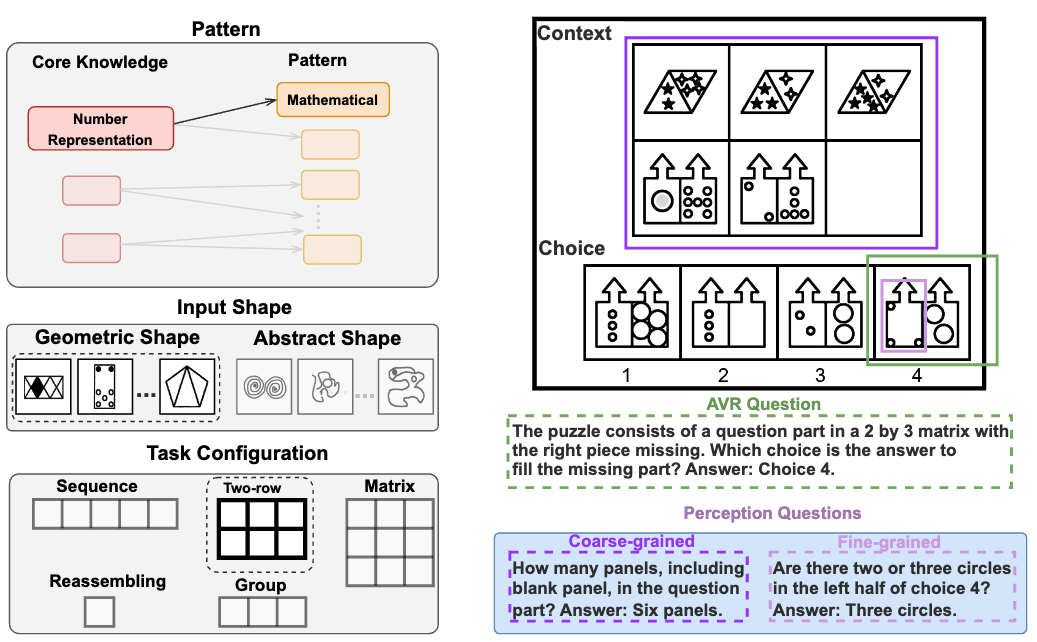
Yifan Jiang*, Jiarui Zhang* Kexuan Sun*, Zhivar Sourati, Kian Ahrabian, Kaixin Ma, Filip Ilievski, Jay Pujara, NeurIPS D&B Track, 2024 arXiv A new comprehensive benchmark, MARVEL, that evaluates multi-modal large language models' abstract reasoning abilities, revealing significant performance gaps between human and SOTA MLLMs. |
|
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
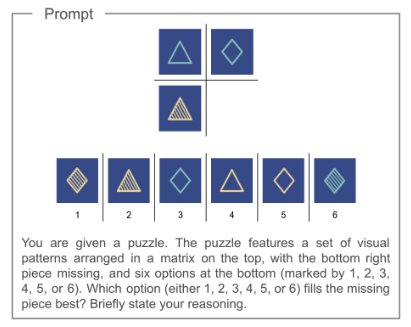
Kian Ahrabian*, Zhivar Sourati*, Kexuan Sun*, Jiarui Zhang Yifan Jiang, Fred Morstatter , Jay Pujara, COLM, 2024 arXiv A study of nonverbal reasoning abilities of multi-modal large language models using variations of Raven's Progressive Matrices. |
|
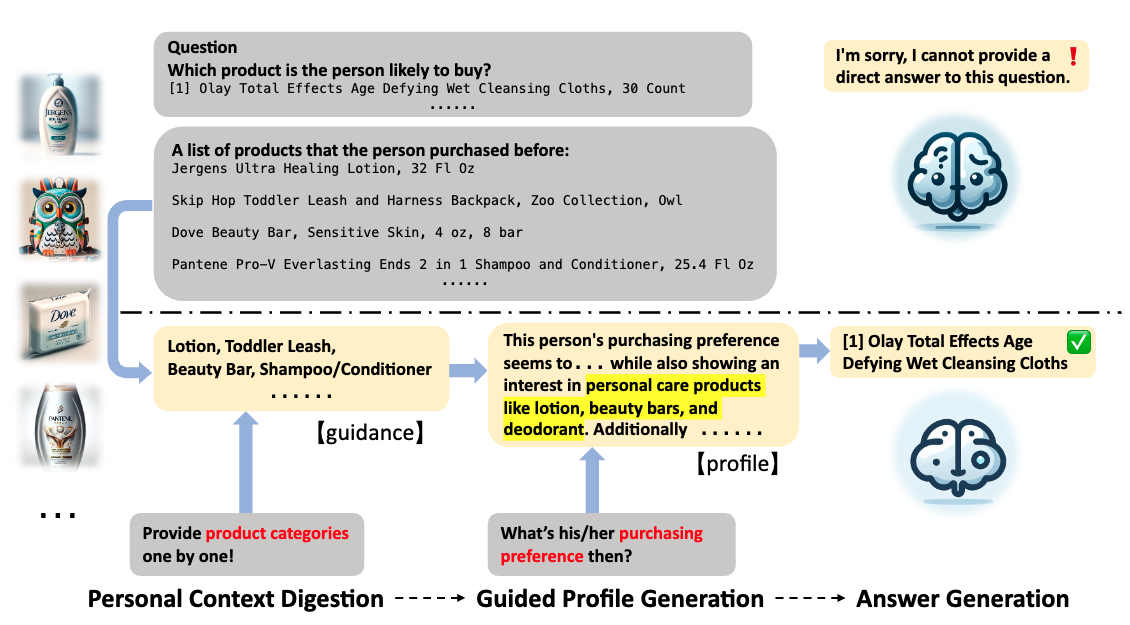
Guided Profile Generation Improves Personalization with Large Language Models
Jiarui Zhang EMNLP Findings, 2024 arXiv We propose guided profile generation to enhance personalization for large language models and evaluate its effectiveness on three popular personalzation tasks. |
|
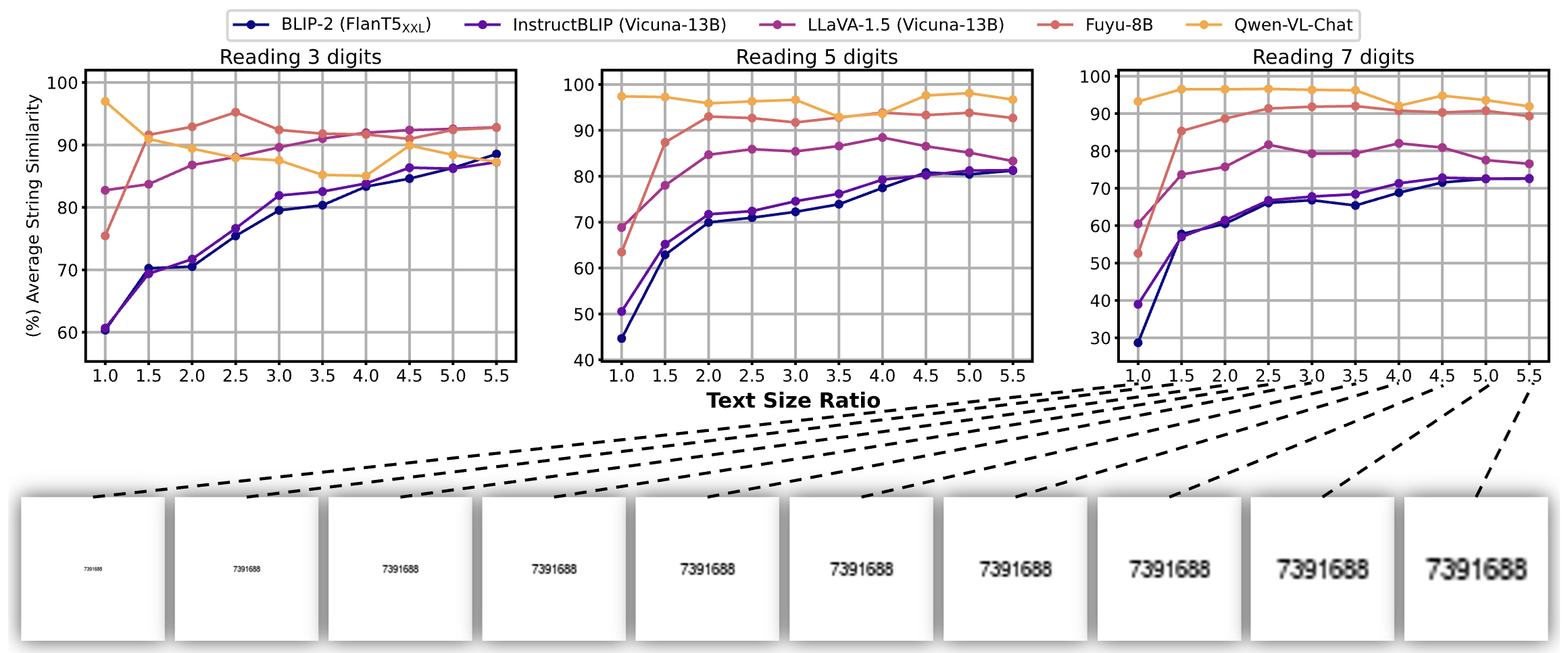
Exploring Perceptual Limitation of Multimodal Large Language Models
Jiarui Zhang*, Jinyi Hu*, Mahyar Khayatkhoei, Filip Ilievski, Maosong Sun arXiv, Github We expose a limitation of several state-of-the-art multimodal LLMs in perceiving small visual objects. Then we identify four factors that influence this limitation, namely, object quality, size, distractor, and location. Through controlled intervention studies, we reveal the distinct impact caused by each factor. Our findings will potentially offer insights to improve visual processing capabilities of MLLMs. |
|
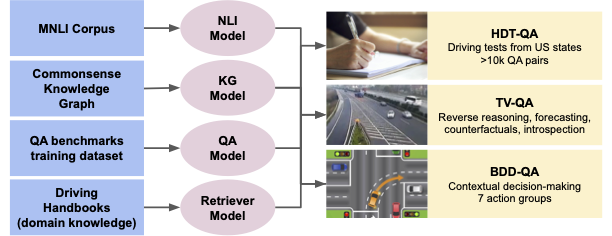
A Study of Situational Reasoning for Traffic Understanding
Jiarui Zhang, Filip Ilievski, Kaixin Ma, Aravinda Kollaa, Jonathan Francis, Alessandro Oltramari, KDD, 2023 arXiv, Github We formalize three novel text-based benchmarks on traffic domain, including decision making, real and hypothetical events casual reasoning, and knowledge testing. Then we study the ability of diverse knowledge-enhanced language models on our benckmarks. |
|
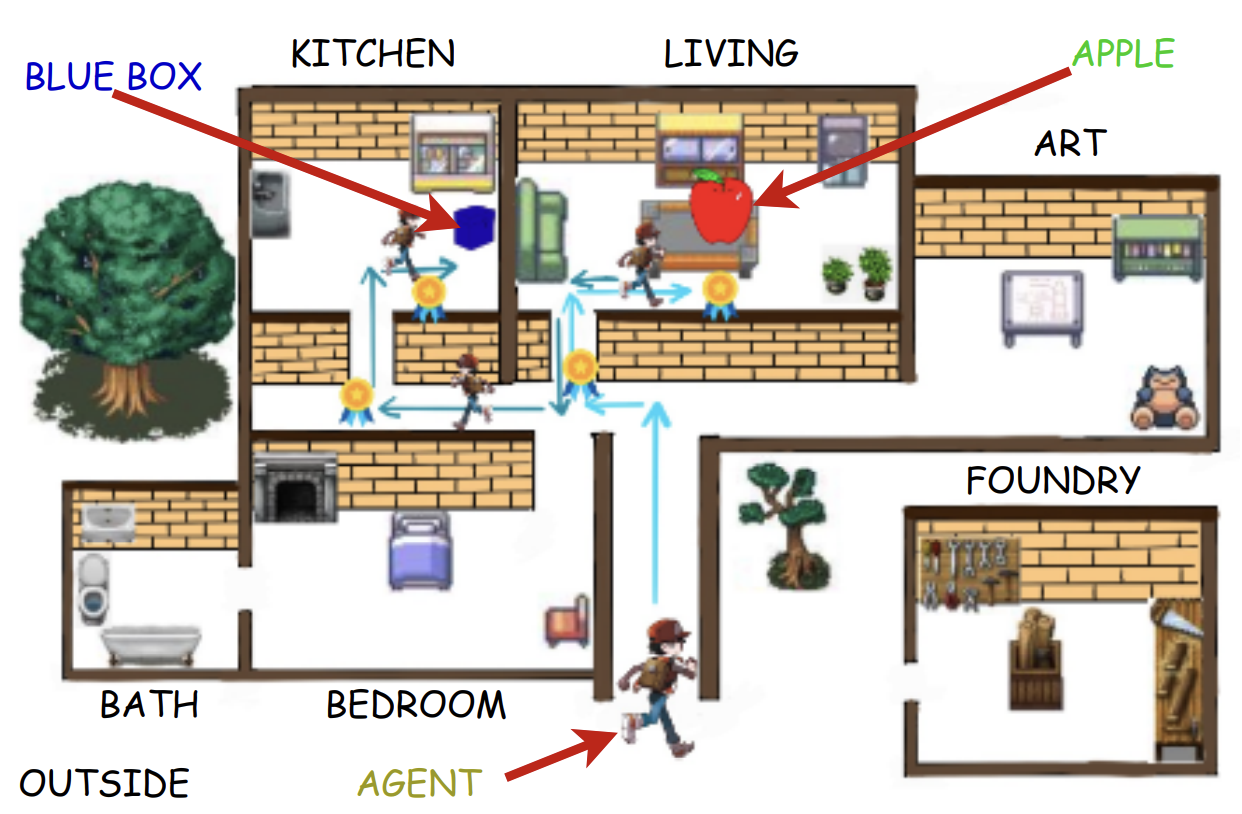
Knowledge-enhanced Agents for Interactive Text Games
Prateek Chhikara, Jiarui Zhang, Filip Ilievski, Jonathan Francis, Kaixin Ma, KCAP, 2023 🏆🏆 Best Student Paper Award 🏆🏆 We introduces a knowledge-injection framework to enhance the functional grounding of agents in text-based games, addressing existing limitations in coherence, contextual awareness, and learning. The framework employs strategies like knowledge graphs and input encoding augmentations. Tested on 10 tasks in the ScienceWorld environment, the study reveals how task properties, model architectures, and domain knowledge interact in interactive contexts. |
|
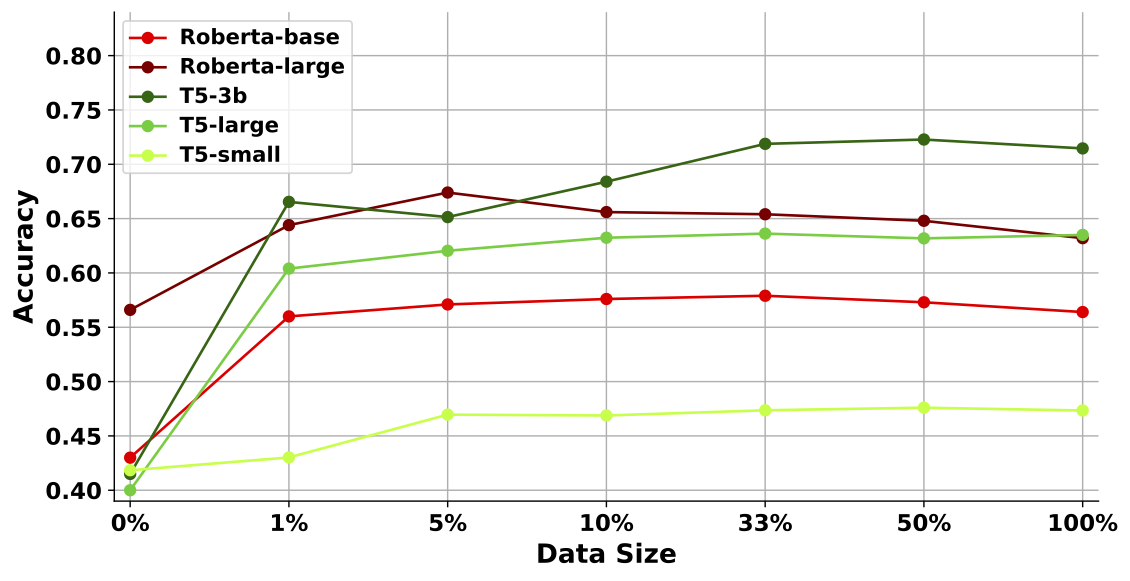
A Study of Zero-shot Adaptation with Commonsense Knowledge
Jiarui Zhang, Filip Ilievski, Kaixin Ma, Jonathan Francis, Alessandro Oltramari, AKBC, 2022 arXiv, Github We train different sizes of language models using synthetic data from knowledge graphs. We observe significant zero-shot performance improvement different language tasks. We also study the effect of knowledge graph training data size and find out more data does not always lead to better performance, and the optimal data size grows with the model size. |
MiscellaneaI enjoy weight lifting in my free time. I also enjoy cooking recently. I like eating burgers. |
|
This website is adapted from here. |